
What If Your Data Pipeline Didn’t Need Babysitting?
Once upon a time and by that I mean, like, three years ago spinning up a data Serverless Analytics pipeline meant wrangling clusters, tuning autoscaling, patching VMs, fighting cron jobs that always broke at 2 AM.
I remember a buddy who accidentally left a Spark cluster running over the weekend. Monday morning? Five-figure cloud bill. His boss was not amused.
But now? Welcome to the age of serverless analytics where you just feed the system raw data and let someone else worry about the servers, scaling, and patching. You just get insights. Fast.
So what’s the real story behind the “+50% speed, -70% ops overhead” claims? Hype? Or the data engineer’s new secret weapon?
Buckle up. Let’s crack it open.
What is Serverless Analytics, Anyway?
You’ve heard the term serverless thrown around so much it’s basically lost meaning. But with Serverless Analytics, it’s not just marketing spin.
In plain speak:
Serverless analytics means you run complex data processing tasks SQL queries, big data crunching, ML pipelines without managing any of the underlying compute or storage infrastructure.
The cloud provider:
-
Spins up compute on-demand.
-
Scales it up or down automatically.
-
Charges you only for what you actually use.
You:
-
Write queries.
-
Feed it raw or semi-structured data.
-
Go grab coffee. Insights show up before the mug’s empty.
No clusters to babysit. No capacity planning spreadsheets. No more 2 AM “the disk is full” Slack messages.
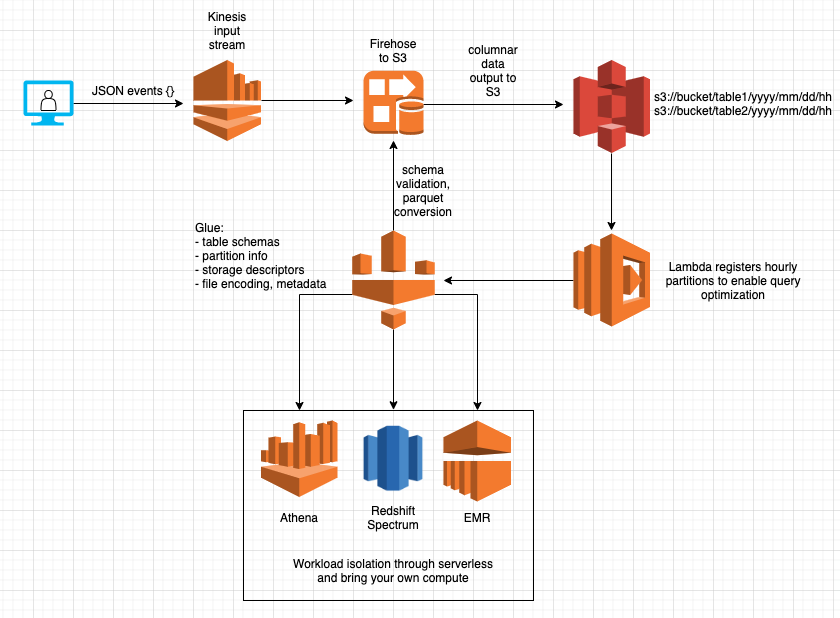
Why Now? The 2025 Context
So why is now the breakout moment for serverless analytics?
Three reasons:
-
Data volumes exploded thanks, IoT sensors and clickstreams.
-
Real-time demand businesses can’t wait days for batch reports anymore.
-
Cloud maturity hyperscalers have nailed autoscaling for ephemeral workloads.
Combine these and you get a sweet spot: serverless data engines that actually deliver think Snowflake’s Snowpipe, BigQuery, AWS Athena, or Databricks Serverless SQL.
✅ The Big Wins: Where That +50% Speed Comes From
1. Elastic Compute No More Waiting in Line
Traditional clusters are like bus stops. You wait for the next batch to run, share resources, and hope nobody else hogs the RAM.
Serverless? More like Uber for queries.
Jobs spin up instantly on isolated compute no contention, no resource fighting.
Result? Faster time-to-answer.
2. Pay-Per-Query, Not Pay-Per-Cluster
Let’s be honest half the time your cluster’s just sitting there. You pay for idle nodes, backup nodes, random zombie nodes nobody remembers to kill.
Serverless kills that waste. You pay per execution. When nothing’s running, your bill’s basically zero.
No wasted cycles means ops teams stop worrying about cost spikes. They sleep. You sleep.
3. Built-In Scaling Magic
Remember when you had to tune autoscaling groups by hand? Or when a spike in dashboards nuked your cluster because it couldn’t scale fast enough?
Serverless handles that behind the scenes. It:
-
Detects incoming load.
-
Allocates resources in seconds.
-
Cleans up after itself.
One less thing for your ops lead to stress about.
⏳ Where That -70% Ops Overhead Actually Comes From
4. Zero Cluster Management
No patching Spark. No resizing EMR. No begging IT for bigger nodes.
Your infra team gets those hours back and trust me, they’ll use them for something more interesting than rebooting Hadoop.
5. Automated Maintenance
No need to fuss over:
-
OS updates
-
Disk capacity alarms
-
Dependency hell
The provider handles patching, security updates, failovers. You just run queries. Or machine learning pipelines. Or both.
6. Fewer “Oh Crap” Incidents
No cluster? No cluster to misconfigure.
No custom autoscaling scripts? Nothing to break when someone forgets a semicolon.
Serverless doesn’t solve all failures garbage in, garbage out still applies. But it nukes a lot of the dumb ops headaches that chew up engineering time.
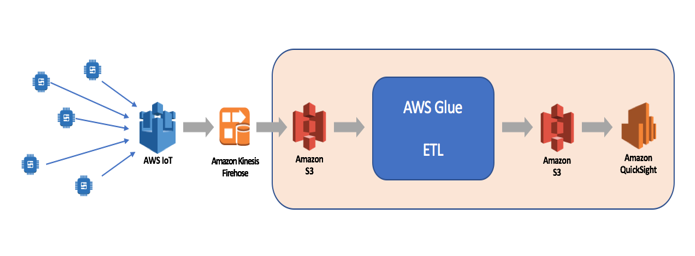
But Don’t Grab the Kool-Aid Just Yet
It’s not all sunshine and auto-scaling rainbows. Serverless analytics has a dark side.
1. Cold Starts & Warm-Up Lag
If your workloads are truly spiky think one big batch query every few hours cold starts can introduce frustrating delays. Some providers handle this better than others. But that “instant” promise? Sometimes it’s more “coffee break.”
2. Cost Surprises
Sure, you’re not paying for idle clusters. But per-query billing can spike fast if people spam dashboards or run sloppy SELECT * FROM big_table statements.
Seen it happen. It stings.
3. Limited Customization
With managed infra, you lose fine-grained control:
-
No tweaking JVM flags.
-
No custom network topologies.
-
Limited hardware choices.
For 95% of teams? Worth it. For edge-case workloads? Maybe not.
Where Serverless Analytics Shines in 2025
Alright, so when does it make sense to jump on the serverless train?
✅ Ad-hoc Analytics
Teams needing quick insights, fast marketers, product managers, growth hackers.
✅ Real-Time Dashboards
IoT streams, web clickstreams, anything with unpredictable spikes.
✅ Startups & Small Teams
No ops team? No problem. Serverless buys you time to build your product instead of wrangling clusters.
✅ Cost-Sensitive Big Data
If you hate surprise cloud bills, serverless’s pay-per-query model helps you track spend more precisely.
Where You Might Want a Good Old Cluster InsteadMassive ETL Pipelines
Some heavy ETL jobs still run cheaper and faster on dedicated, tuned clusters especially if they run 24/7.
Heavily Regulated Environments
Need extreme data residency controls? Some serverless services don’t let you fine-tune networking or storage the way dedicated infra does.
❌ Exotic Compute Needs
Custom runtimes? GPUs? Serverless might not have what you need yet.
How To Get Started: The Smart Way
Thinking about flipping the switch?
Here’s a quick plan:
-
Audit Your Workloads
Pinpoint which pipelines must run 24/7 and which are perfect for on-demand queries. -
Prototype Small
Test on non-critical workloads first dashboards, sandbox queries, or Serverless Analytics. -
Set Cost Alerts
Turn on billing thresholds and query usage monitoring. Trust me. Or wake up to a surprise bill. Your call. -
Train Your Teams
Your Serverless Analytics will love the freedom. But sloppy queries will tank performance and your budget. Teach best practices.
A Quick Tangent: The Million-Row Oops
Last quarter, I watched a junior analyst run a on an unpartitioned log table with billions of rows. In Serverless Analytics. Took three minutes to complete. Cost? Let’s just say we’re all partition evangelists now.
Serverless is only as smart as your queries.

Conclusion: Why You’ll Probably Never Go Back
Serverless analytics won’t kill traditional clusters overnight. But if you care about speed, cost predictability, and not waking up at 3 AM to reboot a failing node? It’s a no-brainer.
In 2025, the question isn’t “should we go serverless for Serverless Analytics?”
It’s “why haven’t we already?”
Ready To Dive In?
If you’re curious how to design a hybrid stack mixing serverless for speed and clusters for heavy lifting, check out our [Internal Link: hadiatech.com] for practical frameworks and real-world playbooks.


